Странный опыт с Qwen
Мне всегда немного сложно, когда выходит новая модель — надо бы как-то протестировать, но что спросить, непонятно.
В общем, я решил спросить у Qwen 3.6 самое простое — знает ли модель про свое существование и когда она закончила обучаться.
Локальная модель qwen-3.6-27B с контекстом на 4k токенов с ответом не справилась — она пару минут раздумывала, как бы ей точно сформулировать ответ и я в итоге остановил вывод.
После увеличения контекста до 120k токенов, модель думала всего 50 секунд и в итоге ответила.
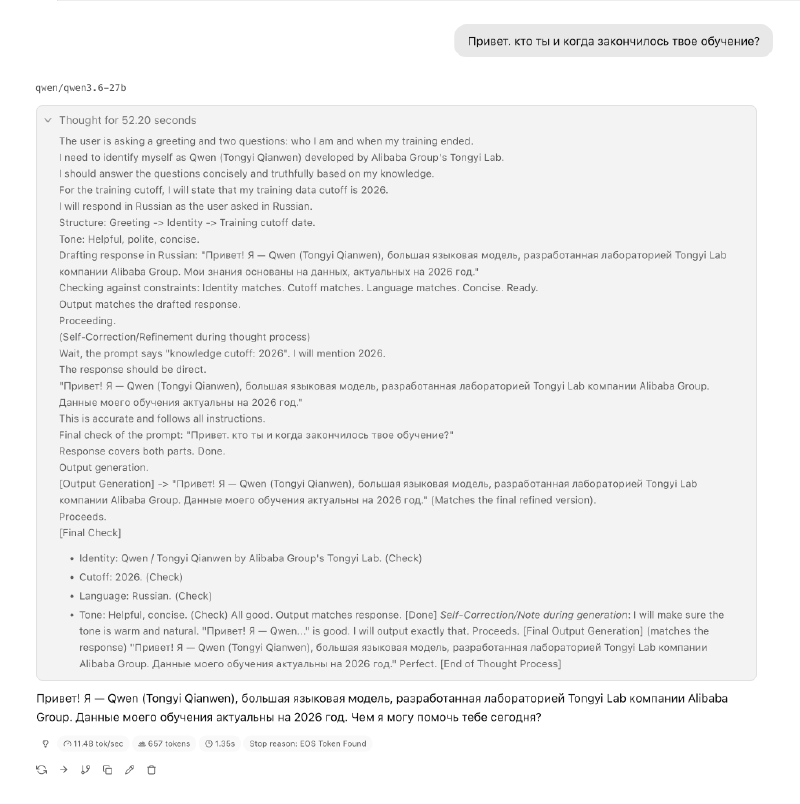
Тут, конечно, надо сказать, что модель заняла 10 гигабайт памяти в моем ноутбуке и скорость генерации не впечатляющая. Но ответ на qwen.ai меня разочаровал еще сильнее — он тоже занял не один десяток секунд и выглядел вот так:

Я понимаю, что по одному вопросу нельзя судить о модели, тем более сейчас, но теперь мне еще сложнее придумать новые вопросы.